WhiteLightning
综合介绍
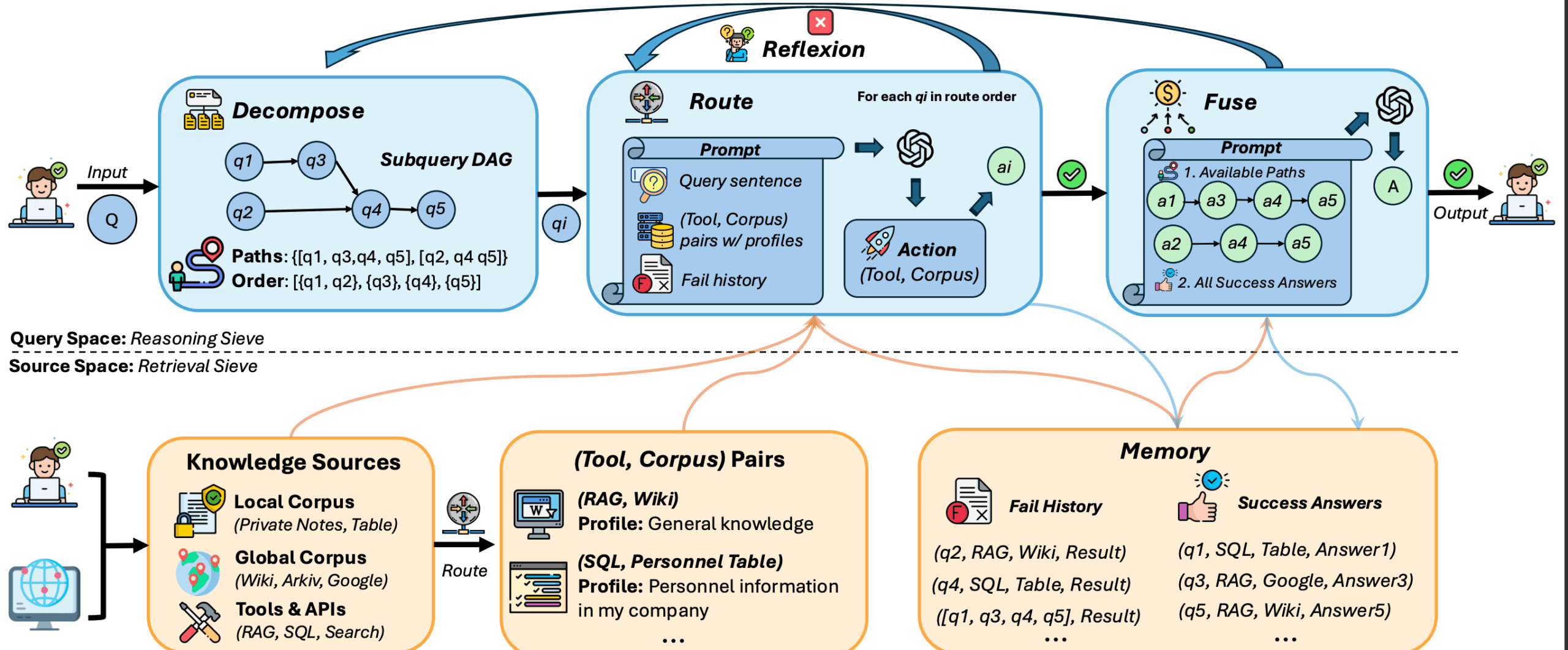
WhiteLightning是一个命令行工具,主要功能是将大型语言模型(如GPT-4o、Claude 4等)的能力,通过模型蒸馏技术,转化为体积小(小于1MB)、运行速度快的轻量级文本分类模型。 这个工具的核心优势在于,它生成的模型采用通用的ONNX格式,可以脱离云端服务,在各种设备上本地运行,包括网页浏览器、移动应用、甚至树莓派等边缘计算设备。 WhiteLightning为开发者提供了一种高效、低成本且注重隐私的解决方案。用户无需准备庞大的数据集,仅通过简单的文本描述,即可训练出专用的AI模型,用于垃圾邮件过滤、情感分析、个人身份信息(PII)检测等多种场景。 该工具由乌克兰的两位开发者创建,并由Inoxoft公司进行维护,采用开源模式,旨在降低开发者在生产环境中使用AI的门槛。
功能列表
- 模型生成与蒸馏: 用户只需提供一句任务描述,WhiteLightning就能利用大型语言模型(LLM)自动生成训练数据,并将其蒸馏成一个体积小于1MB的紧凑型ONNX模型。
- 本地化运行: 生成的模型完全脱离云端API,可以在本地设备上独立运行,有效保护用户数据隐私。
- 跨平台兼容: 基于通用的ONNX格式,模型可以轻松部署在Python, JavaScript, Rust, Java, Swift, C++等多种编程环境中。
- 高性能: 优化后的模型在标准CPU上每秒可处理数千次请求,适用于需要快速响应的应用场景。
- 低成本: 模型训练阶段仅需调用一次LLM,后续的推理过程无持续的API费用,显著降低了使用成本。
- 开源与社区支持: 项目在GitHub上开源,并提供了一个社区模型库,用户可以分享和下载预训练好的模型。
- 自定义数据: 除了自动生成合成数据,工具也支持用户提供自己的数据来训练和优化模型,以满足更专业的应用需求。
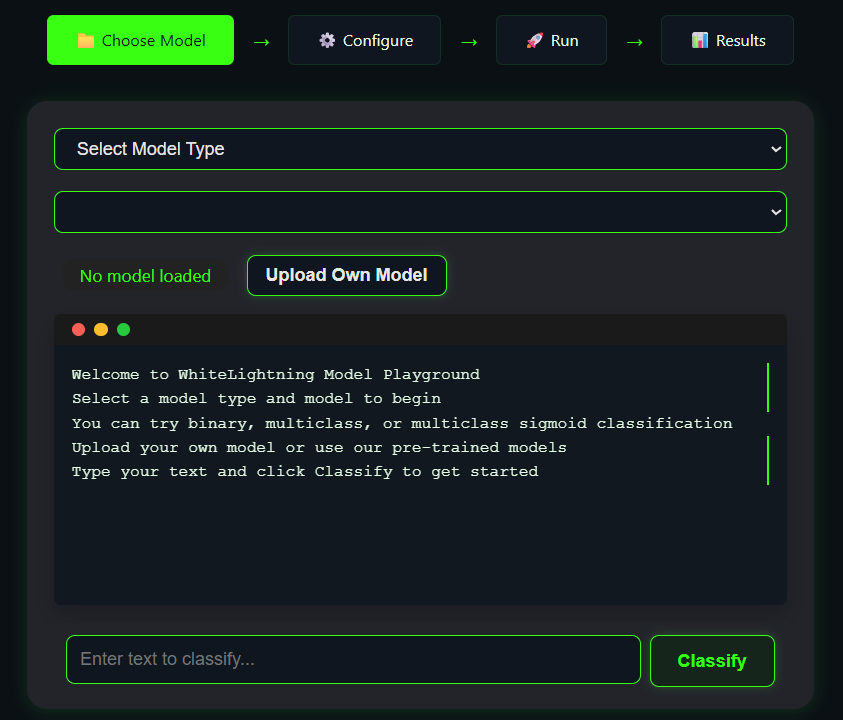
- 浏览器试用: 官方网站提供了一个在线 Playground,用户无需安装任何工具即可快速体验模型生成的效果。
使用帮助
WhiteLightning 是一个命令行界面(CLI)工具,它的设计初衷是让开发者能够通过最简单的操作,快速获得一个轻量级的、可部署在任何地方的AI文本分类模型。以下是详细的使用流程和功能操作介绍:
安装
WhiteLightning 提供了多种安装方式,开发者可以根据自己的工作环境选择最合适的一种。
1. 使用pip(推荐给Python开发者):如果你是Python用户,最直接的安装方式就是通过pip。打开你的终端,运行以下命令:
pip install whitelightning-ai
2. 使用Docker:对于希望在隔离环境中运行或者需要跨平台统一部署的开发者,使用Docker是一个很好的选择。WhiteLightning官方提供了一个即用型的Docker镜像。
首先,拉取最新的Docker镜像:
docker pull ghcr.io/inoxoft/whitelightning:latest
拉取成功后,你就可以通过Docker容器来执行所有whitelightning命令了。
3. 从源码编译:对于希望深入了解其工作原理或进行二次开发的开发者,可以直接从GitHub克隆源码进行安装。
git clone https://github.com/Inoxoft/whitelightning.git
cd whitelightning
pip install .
核心功能操作
安装完成后,你就可以在终端使用whitelightning命令了。其核心操作非常简单,主要围绕whitelightning train这个命令展开。
第一步:定义你的分类任务
你不需要准备繁杂的数据集。你只需要用一句话清晰地描述你的任务目标。例如,我们想创建一个模型来判断用户评论是积极的还是消极的。
第二步:执行训练命令
打开终端,运行以下命令。这个命令告诉WhiteLightning,你需要一个二分类模型(--labels "positive", "negative"),任务是“分析用户反馈的情感”(--task "Classify user feedback as positive or negative"),并将生成的模型文件命名为sentiment_classifier.onnx(-o sentiment_classifier.onnx)。
whitelightning train \
--labels "positive", "negative" \
--task "Classify user feedback as positive or negative" \
-o sentiment_classifier.onnx
命令解析:
--labels: 定义你希望模型输出的分类标签。例如,可以是"spam", "not-spam",或者"question", "bug-report", "feature-request"。--task: 用自然语言描述模型需要完成什么工作。这个描述越清晰,LLM生成的数据质量就越高,最终模型的准确性也越好。-o或--output: 指定生成的ONNX模型文件的保存路径和名称。
执行命令后,WhiteLightning会自动连接到大型语言模型(默认通过OpenRouter选择,如GPT-4o或Claude 4),根据你的--task描述生成上百条高质量的合成训练样本,然后利用这些数据训练出一个轻量级的ONNX模型,并保存到你指定的文件中。整个过程通常在几十秒内完成。
在你的项目中使用模型
模型训练完成后,你得到的是一个.onnx文件。这是一个标准格式的神经网络文件,可以在任何支持ONNX运行时的环境中使用。
Python示例:要在Python项目中使用这个模型,你需要安装onnxruntime库。
pip install onnxruntime```
然后,你可以使用以下代码来加载模型并进行预测:
```python
import onnxruntime as rt
# 加载模型
sess = rt.InferenceSession("sentiment_classifier.onnx")
input_name = sess.get_inputs()[0].name
label_name = sess.get_outputs()[0].name
# 准备预测数据
text_to_classify = "I love this product, it works perfectly!"
# 执行预测
# 注意:输入必须是包含字符串的数组
result = sess.run([label_name], {input_name: [text_to_classify]})
# 输出结果
print(f"The text is: {result[0][0]}")
# 输出可能为:'The text is: positive'
JavaScript (Node.js) 示例:在Node.js环境同样可以运行,需要安装onnxruntime-node。
npm install onnxruntime-node
使用示例代码:
const ort = require('onnxruntime-node');
async function runPrediction() {
const session = await ort.InferenceSession.create('./sentiment_classifier.onnx');
const text = "I love this product, it works perfectly!";
const feeds = {
[session.inputNames[0]]: new ort.Tensor('string', [text], [1])
};
const results = await session.run(feeds);
const prediction = results[session.outputNames[0]].data[0];
console.log(`The text is: ${prediction}`);
}
runPrediction();
高级用法:使用自定义数据
当自动生成的合成数据无法满足特定场景的精度要求时,你可以提供自己的数据集进行训练。你需要将数据整理成一个CSV文件,包含两列:text和label。
例如,创建一个my_data.csv文件:
text,label
"This is an amazing feature!",positive
"The app keeps crashing.",negative
"I'm not sure how to use this.",neutral
然后,在训练时通过--data参数指定文件路径,并更新--labels:
whitelightning train \
--labels "positive", "negative", "neutral" \
--data "my_data.csv" \
-o custom_sentiment_model.onnx
WhiteLightning会使用你提供的数据来训练模型,从而获得一个更贴近你业务场景的分类器。
应用场景
- 垃圾邮件与恶意内容过滤在论坛、评论区或社交媒体应用中,可以训练一个模型来自动识别垃圾广告、恶意链接或不当言论。由于模型在本地运行,可以实现实时的内容审核,且不会将用户数据发送到外部服务器,保护了用户隐私。
- 情感分析企业可以利用此工具快速构建一个情感分析模型,用于分析产品评论、社交媒体反馈或客户支持对话。通过将模型嵌入到内部数据分析平台,可以近乎实时地了解用户情绪,而无需支付昂贵的第三方API费用。
- 意图识别在聊天机器人或智能客服系统中,可以用它来创建一个轻量级的意图识别模型。例如,模型可以判断用户输入是属于“查询订单”、“寻求技术支持”还是“投诉建议”,从而将用户请求路由到正确的处理流程,提升自动化服务效率。
- 个人信息(PII)检测为了保护数据安全与合规,可以训练一个模型来检测文本中是否包含电话号码、邮箱地址、身份证号等敏感个人信息。这个模型可以部署在数据处理的入口端,在信息存入数据库前进行脱敏处理,因为是离线运行,所以特别适合处理高度敏感的数据。
- 物联网与边缘设备在资源受限的边缘设备(如工业传感器、智能摄像头或无人机)上,可以部署一个模型来对设备采集的文本数据进行初步分类和处理。例如,根据日志信息判断设备状态是“正常”、“警告”还是“故障”,从而在网络连接不稳定或断开的情况下也能及时做出响应。
QA
- WhiteLightning和直接使用大型语言模型(LLM)API有什么区别?最核心的区别在于运行环境和成本。直接使用LLM API(如OpenAI API)意味着每次进行文本分类时,都需要将数据通过网络发送到云端服务器,并按调用次数或Token数量付费。而WhiteLightning只在模型“训练”时调用一次LLM来生成数据,之后产出的ONNX模型则完全在本地设备上离线运行,无需网络连接,也无持续的API费用。
- ONNX是什么?为什么选择它?ONNX (Open Neural Network Exchange) 是一个开放的机器学习模型格式。选择它的主要原因在于其出色的跨平台兼容性。一个ONNX模型可以不加修改地在Python、JavaScript、Java、C++等多种语言和框架中运行,这使得开发者可以非常方便地将模型部署到网页、服务器、移动App和嵌入式设备等不同环境中。
- 生成的模型准确率如何?如果不够高怎么办?模型的准确率取决于任务的复杂性和用于生成合成数据的LLM的能力。对于大多数常见的分类任务,其准确率已经足够用于生产环境。如果觉得准确率不满足需求,有两种提升方法:一是优化你的
--task描述,使其更清晰、更具体;二是提供自己的高质量标注数据(通过--data参数),让模型针对你的特定场景进行训练。 - 这个工具是免费的吗?WhiteLightning工具本身是开源且免费的,你可以自由下载和使用。 但在执行
whitelightning train命令时,它会通过后端的OpenRouter服务调用一次大型语言模型(LLM)来生成训练数据,这个过程会产生极少量(通常在1美分左右)的API费用。模型生成后,在任何地方使用这个模型都是完全免费的。 - 我需要具备专业的机器学习知识才能使用它吗?不需要。WhiteLightning的设计目标之一就是降低AI模型的使用门槛。你不需要了解复杂的算法或模型训练流程,只需要用简单的自然语言描述清楚你的分类任务,工具就会自动完成剩下的所有工作。这使得没有AI背景的开发者也能轻松构建自定义的文本分类器。